Introduction
Information architecture helps people to
understand their work field, their relationships with the real world as well as
with the information systems which are supposed to reflect the real world.
Information architecture deals with
objects, their relationships, hierarchies, categories and how to store them in
and retrieve them from applications, files, websites, social media and other
sources I forget to mention…
With the massive expansion of sensor data
rebaptised “the Internet of Things”, social media and linked open data, these
semi structured and unstructured data are adding complexity to the information
architecture.
On the other hand, hypercompetitive
environments force agility upon the larger corporations as the next garage
start-up may overthrow their business model and their dominance in an
incredible short time span. This agility is translated in flexible applications
with point and click business process reengineering.
So how does all this affect the information
architecture development? That is the approach to submit to your judgement in
the next paragraphs.
Analytics, the classical chain of events
In many large organisations, the process
can be described in eight separate stages:
A business question is formulated, e.g. who
are my most loyal customers from the past that may be vulnerable to competitive
offers?
The data analyst starts looking for data
that can contribute to an answer by breaking the business question into related
questions, e.g. which customers have given proof of price sensitivity? Which
customers have shown a downward trend in their net promotor score? Which
customers are reducing their purchases of consumables, Etc…
Gathering the data is the next step: in
transaction systems, market research data, social media, e-mails,…
Manipulating the data: from simple cleaning
and conforming operations to very complex pipeline processing of text and web
URLs to make the data useful for analysis
But before that, visualisation may already
provide intuitive insights: histograms, heat maps, bubble charts and the likes
may show you approaches for further analysis
Analysing the data with the possibilities
offered to analyse text, the old dichotomy between quantitative and qualitative
research has become obsolete. Modern analytics is about hop skip and jump
between the two extremes: quantitative approaches will tell you about the
proportion of clients that may look for greener pastures whereas qualitative
analytics will probe for reasons and root causes.
Interpreting the data may follow more
intuitive paths where extra information is added, opinions are collected using
the Delphi technique or other qualitative approaches to add useful meaning and
actionable insights to the analysis. E.g. developing a customer scoring model
that is broadly used and understood in the organisation.
The hardest part is the last phase:
integrate the data and the analytics in the decision making process. To
conclude with our example: developing scripts and scenarios for the call centre
agents that pop up whenever a client with a potential defection risk calls the
company.
Architecture development, the classical
chain of events
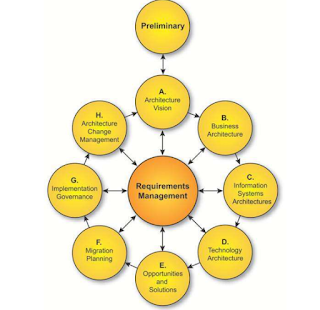 |
| TOGAF's Architecture Dvelopment Method |
At the heart of Enterprise Architecture
development is the management of requirements. These requirements are
predominantly based on process support.
User stories like “As a call centre agent,
I want to see the entire customer history when call comes in in order to serve
the customer better” are process support requirements. The data are defined
within the context of the process. In this comprehensive case, some level of
enterprise class da ta is attained but
what about more microscopic user stories like “As a dunning clerk I want to see
the accounts receivable per customer sorted per days overdue”. In this case, no
context about why the customer is overdue is in scope. Maybe the delivery was
late or incorrect, maybe the customer has a complaint filed with customer
service or maybe the invoice was sent late and arrived during the client’s
holiday closing…
Yes, we have a shifting paradigm!
I know, in this business the paradigm
notion is an overrated concept, abused for pouring old wine in new bags. But in
Thomas Kuhn’s strict definition of the term, I think we do stand a chance of
dealing a with a paradigm shift in information architecture development.
 |
| A must read for anyone in information technology |
I see critical anomalies:
inconsistent decision making depending on
the flavour of the day and the profile of the decision maker, often based on
inconsistent information which is extracted from inconsistent data. With a time
to market reducing to smaller and smaller timeframes, the old process based
architecture development method may prove to be ineffective to meet the
challenges of new entrants and substitute products and services. Although every
pundit is touting that information is the new oil, not too many companies are
using it as the basis of information architecture development.
The old top down view leads to
underperforming data retrieval which is no more sustainable in a digital
competitive environment where time to market is often equal to the time it
takes to tailor data to your needs, e.g. recommenders in e-business, cross
selling in retail, risk assessment in insurance,…
There’s external pressure from the GDPR
By now every organisation doing business
with or in the EU will be aware of the 25th May 2018, date when the
general data protection regulation or GDPR, comes into effect which requires:
valid and explicit consent for the use of
any data that can identify a person,
data protection by default (anonymization,
pseudonymisation and security measures for data,
data breaches communication to the
authorities and
records of processing activities.
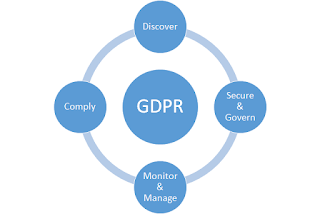 |
| Data management activities needed for compiance with the new legislation |
This requires organisations to manage their
data on individuals far better and more centralised than they did in the past. Data
requirements on persons will be at the heart of the information architecture
development cycles as dealing with those on a lower level in the architecture
framework will be a sure recipe for disaster.
Technology also contributes to this new
approach
At least three technology evolutions enable
the data centric approach to information architecture development:
microservices, master data management tools and hybrid databases.
Microservices enable rapid scaling and
reengineering of processes. The use of consistent data throughout the
microservices architecture is a prerequisite.
Master data management tools are maturing
as each relevant player is expanding from its original competence into the two
others. You can observe data governance tools adding data quality and master
data management functionality as well as data quality tools developing master
data management and governance services and… you know where this is going.
Last but not least, hybrid databases will
enable better storage and retrieval options as they support both transactional
and analytical operations on structured and unstructured data.
In conclusion: modern information
architecture needs flexible and fluid process management support using
consistent data to facilitate consistent decision making, both by humans and
machines.
In the next post, I will use a case to
illustrate this approach. In the meantime, I look forward to your remarks and
inputs for a thorough discussion.




















